


V-Nova and PresenZ released a short film demonstrating upcoming applications of immersive media for the metaverse combining 6DoF volumetric video with point-cloud compression.

Data compression specialist V-Nova and immersive media software developer PresenZ released a short film in the Steam Store in November 2021 to demonstrate upcoming applications of immersive media for the metaverse. The project uses V-Nova’s point-cloud compression combined with PresenZ’s 6DoF volumetric video format.
Guido Meardi, V-Nova’s CEO and Co-Founder talked to Digital Media World about the project and his company’s role in making it possible to deliver a volumetric film to end users’ VR headsets. While the formats and techniques for producing such productions are advancing well, distributing the huge quantities of data they generate, at high quality, remains an interesting challenge. He also shares intriguing ideas about what makes their work relevant to navigating the metaverse into the near future.
First, take a moment to understand PresenZ’s 6DoF format. The PresenZ format achieves the same visual fidelity familiar to audiences in photoreal CGI and visual effects, 3D animated feature films or high-end industrial previsualisation, by integrating itself into the same creation pipelines.
By applying their proprietary rendering process to the existing 3D animated movie ‘Construct’, a team from PresenZ created an immersive 6DoF adaptation for viewing in a VR headset. ‘Construct’ is a short film project by director and VFX artist Kevin Margo, originally developed between 2014 and 2018 to pioneer the use of virtual production techniques combined with motion capture and real-time rendering.
From 3D to Volumetric
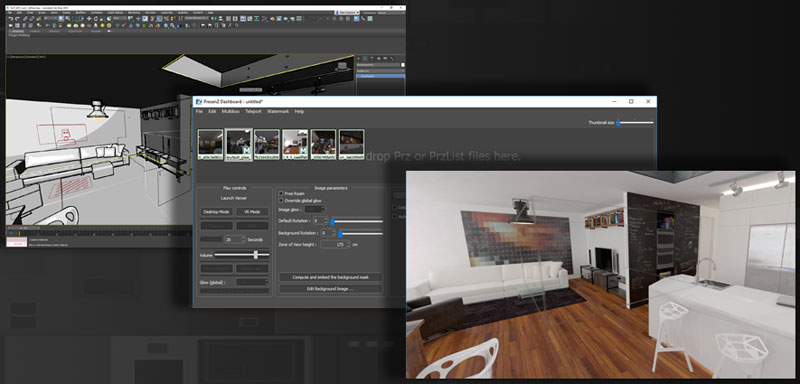
Developers can transform 3D assets into an immersive volumetric experience for audiences using the PresenZ format. It renders images from within a volume defined inside a 3D scene, rather than from a single point-of-view (POV), or camera position, which is how the images in a regular 360° VR project are rendered. PresenZ calls the defined volume a Zone of View (ZOV).

PresenZ renders from inside a Zone of View, instead of through a single-perspective camera.
Normally, viewers watching a 360° VR experience are placed at the centre of a scene. They can turn their heads, but cannot choose from which spot or angle to look at the scene. A volumetric image, on the other hand, is an image with 6 degrees of freedom (6DoF), which means the viewer is able to change his or her position inside the image, move closer to objects or characters, and move around them. Objects that are obscured from one point, become visible from another.
In effect, the viewer becomes the cameraman and experiences a deeper sense of immersion inside the scene. To make this happen, PresenZ renders from inside the Zone of View, gathering all the information needed to show whatever is going to be visible from any POV within this zone.
More Motion, More Data
The ZOV’s position, orientation and size is defined by the developer, replacing the standard single-perspective camera. Viewers can move freely inside the ZOV and look in any direction, which is great for the viewer but it does mean that, the bigger the zone of view, the more data has to be created to a good level of detail and finish, collected and manipulated. Consequently, render time is typically twice as long as a 360° render, depending on its complexity.
The greatest benefit of 6DoF rendering is that, unlike standard 360° VR movies, it can realistically respond to the position and orientation of the VR headset, so you can get closer to objects and characters. Users can explore and look around more naturally, but without the motion sickness commonly associated with VR. With approaches like the PresenZ format available, developers can push the capabilities of digital media and metaverse applications, and make experiences based on 3D/CGI assets more immersive.
The Distribution Challenge
Rendering the huge amounts of data needed for volumetric projects is one challenge. Distributing it and making it viewable through VR gaming headsets is another. That is the goal of V-Nova’s point-cloud compression – compressing hundreds of gigabytes of data to transform the movie into a manageable asset, ready for distribution, real-time decoding and consumption on VR setups at high quality.
Guido said, “Each point in a similarly photorealistic point cloud has tens of attributes, some of them requiring up to 16-bit values for sufficient precision. Preserving the data in the PresenZ files involved managing, on average, 22 or more attribute layers.” Achieving competitive performance with volumetric data when compared to other techniques, V-Nova’s point cloud compression is built on their MPEG-5 LCEVC SDK, and their SDK for compression standard VC-6 (SMPTE ST 2117-1).
Low Complexity Enhancement
V-Nova LCEVC (Low Complexity Enhancement Video Coding) is an SDK for enhancing encoding and decoding workflows with MPEG-5 Part 2 LCEVC. LCEVC increases the compression efficiency of existing or future video codecs, to achieve higher quality at lower bitrates. The LCEVC SDK has a decoder integration layer that allows direct integration into players on different kinds of devices, and includes optimisations to take advantage of various CPUs and GPUs.

V-Nova's LCEVC in use, streaming sports video feeds.
LCEVC works by encoding a lower resolution version of a source image using an existing, base codec, and then encodes the difference between the reconstructed lower resolution image and the source, using a different compression method, which is the enhancement.
The details that make up the difference are known as residual data. LCEVC uses tools specifically designed to efficiently compress residual data on two or more layers, one at the resolution of the base to correct artifacts caused by the base encoding process, and one at the source resolution that adds details to reconstruct the output frames. Between those two reconstructions, the picture is upscaled.
So, as an enhancement codec, LCEVC not only upsamples effectively – it can also encode and compress the residual information necessary for true fidelity to the source. LCEVC can produce mathematically lossless reconstructions as well, meaning ALL of the information can be encoded and transmitted and the image perfectly reconstructed.
Resolution Hierarchy
V-Nova’s VC-6 SDK handles encoding and decoding of the SMPTE VC-6 ST-2117 codec standard on many types of devices. Based on repeatable s-trees as the core compression structure, instead of the usual block-based transforms, it works by creating an image in a range of different resolutions in a hierarchy, and then encodes the residual data – or differences – between the levels with a low-complexity approach.
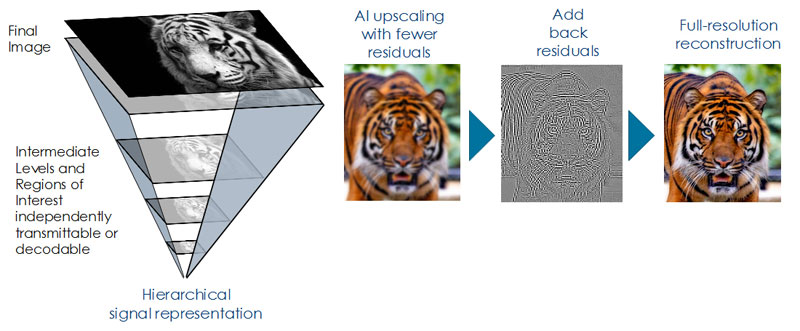
S-trees are made up of nodes arranged in a tree structure in which each node links to multiple nodes in the next level. Compression is achieved using metadata to signal whether levels can be predicted by selectively carrying enhancement data in the bitstream. The more data that can be predicted, the less information will have to be sent, and the better the compression ratio – not having to send any actual data for an area of the picture is the ideal. VC-6 metadata allows large numbers of these S-trees to be omitted from even detailed layers.
VC-6’s hierarchical structure also means you only need decode up to the resolution you need from the different layers within the file, using less bandwidth and speeding up transfer times. It also removes the need to separately encode proxies or preview versions and allows you to archive the full masters and devote hot storage to working on lower resolutions.
Bitstream Navigation
A key feature is the ability to navigate spatially within the VC-6 bitstream at multiple levels or resolutions. In other words, a single bitstream can be decoded at multiple, different resolutions within the decoder. A decoder can decide, from a single source stored file, for each region-of-interest, the level of enhancement and resolution to decode based on the network properties. Or, your decoding device could use this property to apply more quality and resolution to different regions of the image interactively, directly from the stored compressed asset without first restoring the full-resolution image.
This kind of compression suits VR and AR applications, for which an encoder might compress a particular scene with a single bitstream covering the overall field of view. A low latency decoder can navigate within the bitstream to locate the portion of the high resolution master that the viewer is inspecting and dedicating more resources to decoding that portion of the image than it would to the viewer’s peripheral vision. As the viewer’s head moves, the decoder continues to perform the same algorithm.

Because using s-tree metadata to predict large numbers of grid values from the lower layers of the tree is a highly parallel process, VC-6 is designed to use the CPUs and GPUs built into users’ devices to support encoding and decoding. As mentioned above, the same is true of MPEG-5 LCEVC. Both can work in software but, by accessing massive parallelism, also take advantage of dedicated graphics hardware.
Speed Test
For the ‘Construct’ project, V-Nova applied 2/3 mathematically lossless compression, encoding at the rate of 20GB/10mins. “‘2/3 mathematically lossless’ means that certain data components of the point cloud and related attributes are compressed losslessly, while others are compressed near losslessly – that is, lossy coding,” said Guido. “Also, ‘Construct’ is particularly complex. Other, simpler volumetric videos need much lower data rates.”
He also mentioned the speed factor. Compression efficiency relates to speed. For a given coding format, the faster the data is encoded, the more you need to cut corners and/or disable certain efficiency tools, which means compression rates will suffer.

“For instance, there is no absolute coding efficiency for H.264 or any other coding format. Watching a movie on Netflix may use the same H.264 format as a Zoom videocall, but Netflix will address the problem with processing power and use content-adaptive encoding. Conversely, Zoom has to encode everything in real time without much headroom for sophisticated decision-making, creating more opportunities for errors.
“A 1080p50 video has 3 Gbps of data uncompressed, and around 8-10 Mbps compressed. Normal compression removes at least 99.8% of the original file size, but making even one small mistake may downgrade that rate to 99.6%. That still seems quite efficient, and yet you are left with 0.4% instead of 0.2% of the original file size, or twice as much data. Thus, compression is in many ways a game of ‘not making mistakes’.”
The Volumetric Metaverse
A new desire to use the metaverse to communicate with volumetric elements and holograms now more closely associates compression and graphics rendering. “So far, graphics rendering has been relevant for 3D environments like game worlds that people playing a multiplayer game would downloaded onto a device, once and for all, and very rarely update. From there, they would only need to exchange minimal gaming data,” Guido said.

“But the metaverse, which is largely about enhanced digital communication and real-time interactions, aims to become a new user interface to access distributed data – that is, data that resides outside your local system – in real time. It has the potential to be a new way to browse the internet and for people to interact with one another and/or with remote devices, not just for entertainment but also for work.
“As such, we will need to receive and exchange both video feeds – since video cameras will continue to be an important class of sensors for at least the next 20 years – and volumetric data. Both will be rendered in 3D space, either immersively via VR headsets or via AR glasses superimposing elements onto what we see.”
Beyond Big VR Headsets
He notes that the metaverse is not just for early-adopter enthusiasts wearing big VR headsets. It will connect headsets, but also light AR glasses, tablets, mobile phones and smart watches, and involve interacting with the metaverse from standard flat displays, while using a volumetric UI – probably similar to a video game UI – instead of an ordinary flat UX.

In such a future, not only will compression and graphics rendering be closely related, but it’s reasonable to expect layered coding of information to be used as well. For distant elements, either flat screens showing conventional video or volumetric objects like avatars, receiving and decoding fine detail won’t be necessary. But if we get closer, we may want all those details, if only for the part that we are observing at a given moment.
“Those kinds of optimisations will be what makes almost unmanageable quantities of data transmissible and decodable, while leaving enough processing headroom for the graphics rendering itself,” Guido said. “Finally, since rendering and display seem likely to be decoupled soon, once this whole process is completed in an edge device with enough parallel processing power, an ultra-low-latency video casting feed will be shot to the viewer’s display device of choice.” www.v-nova.com